This federates over the writing of diagnostic and prognostic data to the file system. It also manages the time manipulation of fields and groups. More...
Functions/Subroutines | |
| subroutine, public | initialise_writer_federator (io_configuration, diagnostic_generation_frequency, continuation_run) |
| Initialises the write federator and configures it based on the user configuration. Also initialises the time manipulations. More... | |
| subroutine, public | finalise_writer_federator () |
| Finalises the write federator and the manipulations. More... | |
| subroutine, public | inform_writer_federator_time_point (io_configuration, source, data_id, data_dump) |
| subroutine, public | inform_writer_federator_fields_present (io_configuration, field_names, diag_field_names_and_roots) |
| Informs the writer federator that specific fields are present and should be reflected in the diagnostics output. More... | |
| logical function, public | is_field_used_by_writer_federator (field_name, field_namespace) |
| Determines whether a field is used by the writer federator or not. More... | |
| logical function, public | is_field_split_on_q (field_name) |
| Determines whether a field is split on Q or not. More... | |
| subroutine | enable_specific_field_by_name (field_name, diagnostics_mode, expected_here) |
| Enables a specific field by its name, this will locate all the fields with this name and enable them. More... | |
| subroutine, public | provide_q_field_names_to_writer_federator (q_provided_field_names) |
| Provides the Q field names to the write federator, this is required as on initialisation we don't know what these are and only when MONC register do they inform the IO server of the specifics. More... | |
| subroutine, public | provide_ordered_field_to_writer_federator (io_configuration, field_name, field_namespace, field_values, timestep, time, source) |
| subroutine | provide_ordered_field_to_writer_federator_real_values (io_configuration, field_name, field_namespace, field_values, timestep, time, source) |
| Provides fields (either diagnostics or prognostics) to the write federator which will action these as appropriate. This will split Q fields up if appropriate. More... | |
| integer function | get_size_of_collective_q (io_configuration, field_name, source) |
| Retrieves the data size for each Q entry of a collective Q field for the specific source MONC that has sent data. More... | |
| subroutine | provide_ordered_single_field_to_writer_federator (io_configuration, field_name, field_namespace, field_values, timestep, time, source) |
| Provides a single ordered field, i.e. Q fields have been split by this point. More... | |
| subroutine | write_collective_write_value (result_values, writer_index, contents_index, source, lookup_key) |
| Writes the collective values, this is held differently to independent values which are written directly - instead here we need to store the values for each MONC hence a specific type is used instead. More... | |
| subroutine | determine_if_outstanding_field_can_be_written (io_configuration, writer_entry, specific_field) |
| For a specific field wil determine and handle any outstanding fields writes until an outstanding write can not be performed or the outstanding list is empty. More... | |
| subroutine | determine_if_field_can_be_written (io_configuration, writer_entry, specific_field, timestep, previous_write_timestep, write_time, previous_write_time, field_written) |
| Determines if a file can be written to its overarching write representation. If so then a write is issued, otherwise an outstanding write point is registered which will be checked frequency to do a write later on. More... | |
| subroutine, public | check_writer_for_trigger (io_configuration, source, data_id, data_dump) |
| Checks all writer entries for any trigger fires and issues the underlying file storage. More... | |
| subroutine | check_writer_trigger (io_configuration, writer_entry_index, timestep, time, terminated) |
| Checks a writer trigger and issues a file creation along with field write if the conditions (time or timestep) are met. This will either create and write to the file or store a pending state if one is already open (required due to NetCDF/HDF5 limitations with thread safety and parallel access.) More... | |
| subroutine, public | issue_actual_write (io_configuration, writer_entry, timestep, time, terminated_write) |
| Issues the actual file creation, write of available fields and closure if all completed. More... | |
| subroutine | clean_time_points () |
| Cleans out old timepoints which are no longer going to be of any relavence to the file writing. This ensures that we don't have lots of stale points that need to be processed and searched beyond but are themselves pointless. More... | |
| type(map_type) function | extract_applicable_time_points (start_time, end_time) |
| Extracts the applicable time points from the overall map that lie within a specific range. More... | |
| type(map_type) function | sort_applicable_time_points (unsorted_timepoints) |
| Sorts the time points based upon their timestep, smallest to largest. Note that this is a bubble sort and as such inefficient, so would be good to change to something else but works OK for now. More... | |
| subroutine | close_diagnostics_file (io_configuration, writer_entry, timestep, time) |
| Closes the diagnostics file, this is done via a global callback to issue the closes synchronously (collective operation) More... | |
| subroutine | handle_close_diagnostics_globalcallback (io_configuration, values, field_name, timestep) |
| Call back for the inter IO reduction which actually does the NetCDF file closing which is a collective (synchronous) operation. Calls out to the NetCDF code to do the call and then checks the list of pending file writes to process any others that are waiting in the queue. More... | |
| logical function | check_for_and_issue_chain_write (io_configuration, writer_entry) |
| Will check whether there are any pending writes and if so will issue a chain write for this. More... | |
| subroutine | register_pending_file_write (writer_entry_index, timestep, time, terminated_write) |
| Registers a pending file write which will be actioned later on. More... | |
| logical function | get_next_applicable_writer_entry (field_name, field_namespace, writer_index_point, contents_index_point) |
| Retrieves the index of the next writer which uses a specific field. If none is found then returns false, otherwise true. More... | |
| integer function | get_total_number_writer_fields (io_configuration, writer_entry_index) |
| Determines the total number of fields that make up a writer entry, this is all the fields of the groups that make up this writer and individual fields specified too. More... | |
| integer function | get_group_number_of_fields (io_configuration, group_members, num_q_fields, namespace) |
| Retrieves the number of fields within a group of fields. More... | |
| integer function | get_field_number_of_fields (io_configuration, field_name, field_namespace, num_q_fields) |
| Retrieves the number of fields that make up this field, if it is a Q field then it will be split into many subfields hence it is not a simple 1-1 mapping. More... | |
| integer function | add_group_of_fields_to_writer_entry (io_configuration, writer_entry_index, facet_index, current_field_index, writer_field_names, duplicate_field_names, diagnostic_generation_frequency) |
| Adds a group of fields to a writer entry, groups are expanded out into individual fields, each inherit the properties of the group. More... | |
| integer function | add_field_to_writer_entry (io_configuration, writer_entry_index, io_config_facet_index, my_facet_index, field_name, field_namespace, writer_field_names, duplicate_field_names, diagnostic_generation_frequency) |
| Adds a field to the writer entry, this will split the Q fields. However at initialisation we don't know what the Q fields are called, hence place a marker which will be replaced later on. More... | |
| subroutine | add_specific_field_to_writer_entry (io_configuration, writer_entry_index, io_config_facet_index, my_facet_index, field_name, field_namespace, writer_field_names, duplicate_field_names, timestep_frequency, diagnostic_field_configuration, prognostic_field_configuration) |
| Adds a specific field and its information to a writer entry. More... | |
| subroutine | handle_duplicate_field_names (writer_entry, duplicate_field_names) |
| Marks duplicate field names in a writer entry as duplicates so that the NetCDF layer can then deal with this by issuing unique names. More... | |
| integer function | get_index_of_group (io_configuration, group_name) |
| Searches the IO server configuration for a group with a specific name and returns the index to that group or 0 if no corresponding group is found. More... | |
| subroutine | determine_collective_type_and_optimise_if_possible (io_configuration, field_to_write_information) |
| Determines whether it can optimise a specific collective field. If the field fits into certain limited parameters then it will optimise it. These parameters are very common, hence most fields can be optimised. Basically, it is looking to contiguous blocks of data from different MONCs so that the number of writes to the NetCDF file is limited. More... | |
| subroutine | initialise_contiguous_data_regions (io_configuration, field_to_write_information) |
| Will initialise the collective data regions that form contiguous blocks within the data. This is quite an expensive operation so only done once for each field, but has the potential for very significant performance advantages for the fields that match it. More... | |
| subroutine | get_common_starts (dim, val, vals, common_starters, num_common) |
| Retrieves the number of common starting points that match a specific input value. More... | |
| integer function | get_dimension_identifier (dim_name, is_auto_dimension) |
| Translates a dimension name to its numeric corresponding identifier. More... | |
Variables | |
| type(writer_type), dimension(:), allocatable, volatile | writer_entries |
| type(hashset_type), volatile | used_field_names |
| type(hashset_type), volatile | q_field_names |
| type(hashmap_type), volatile | time_points |
| type(hashmap_type), volatile | q_field_splits |
| type(hashmap_type), volatile | collective_q_field_dims |
| integer, volatile | time_points_rwlock |
| integer, volatile | collective_contiguous_initialisation_mutex |
| integer, volatile | currently_writing_mutex |
| logical, volatile | currently_writing |
Detailed Description
This federates over the writing of diagnostic and prognostic data to the file system. It also manages the time manipulation of fields and groups.
Function/Subroutine Documentation
◆ add_field_to_writer_entry()
|
private |
Adds a field to the writer entry, this will split the Q fields. However at initialisation we don't know what the Q fields are called, hence place a marker which will be replaced later on.
- Parameters
-
io_configuration The IO server configuration writer_entry_index Index of the writer entry that we are dealing with io_config_facet_index Index of the facet (group) in the IO server configuration my_facet_index The current field index in this internal module representation of the structure field_name The name of the field that we are constructing writer_field_names The field names in the writer (for duplication checking) duplicate_field_names Duplicate field names in the wrier, for duplication checking diagnostic_generation_frequency Generation frequency of the diagnostics
- Returns
- Location for next field to be written to
Definition at line 1181 of file writer_federator.F90.


◆ add_group_of_fields_to_writer_entry()
|
private |
Adds a group of fields to a writer entry, groups are expanded out into individual fields, each inherit the properties of the group.
- Parameters
-
io_configuration The IO server configuration writer_entry_index Index of the writer entry that we are dealing with facet_index Index of the facet (group) in the IO server configuration current_field_index The current field index in this internal module representation of the structure
- Returns
- The next field index to write to
Definition at line 1142 of file writer_federator.F90.


◆ add_specific_field_to_writer_entry()
|
private |
Adds a specific field and its information to a writer entry.
- Parameters
-
io_configuration The IO server configuration writer_entry_index Index of the writer entry that we are dealing with io_config_facet_index Index of the facet (group) in the IO server configuration my_facet_index The current field index in this internal module representation of the structure field_name The name of the field that we are constructing writer_field_names The field names in the writer (for duplication checking) duplicate_field_names Duplicate field names in the wrier, for duplication checking timestep_frequency Timestepping frequency diagnostic_field_configuration The diagnostic field configuration (optional) prognostic_field_configuration The prognostic field configuration (optional)
Definition at line 1279 of file writer_federator.F90.

◆ check_for_and_issue_chain_write()
|
private |
Will check whether there are any pending writes and if so will issue a chain write for this.
- Parameters
-
io_configuration The IO server configuration writer_entry The specific writer entry
- Returns
- Whether a chain write was issued or not
Definition at line 962 of file writer_federator.F90.

◆ check_writer_for_trigger()
| subroutine, public writer_federator_mod::check_writer_for_trigger | ( | type(io_configuration_type), intent(inout) | io_configuration, |
| integer, intent(in) | source, | ||
| integer, intent(in) | data_id, | ||
| character, dimension(:), intent(in), allocatable | data_dump | ||
| ) |
Checks all writer entries for any trigger fires and issues the underlying file storage.
- Parameters
-
io_configuration Configuration of the IO server source The source PID of the MONC process data_id The ID of the data definition that is represented by the dump data_dump The data we have received from MONC
Definition at line 642 of file writer_federator.F90.

◆ check_writer_trigger()
|
private |
Checks a writer trigger and issues a file creation along with field write if the conditions (time or timestep) are met. This will either create and write to the file or store a pending state if one is already open (required due to NetCDF/HDF5 limitations with thread safety and parallel access.)
- Parameters
-
io_configuration The IO server configuration writer_entry_index Index of the writer we are concerned with timestep The corresponding timestep time The corresponding model time
Definition at line 674 of file writer_federator.F90.

◆ clean_time_points()
|
private |
Cleans out old timepoints which are no longer going to be of any relavence to the file writing. This ensures that we don't have lots of stale points that need to be processed and searched beyond but are themselves pointless.
Definition at line 784 of file writer_federator.F90.

◆ close_diagnostics_file()
|
private |
Closes the diagnostics file, this is done via a global callback to issue the closes synchronously (collective operation)
- Parameters
-
io_configuration The IO server configuration writer_entry The writer entry timestep The file write timestep time The file write time
Definition at line 880 of file writer_federator.F90.
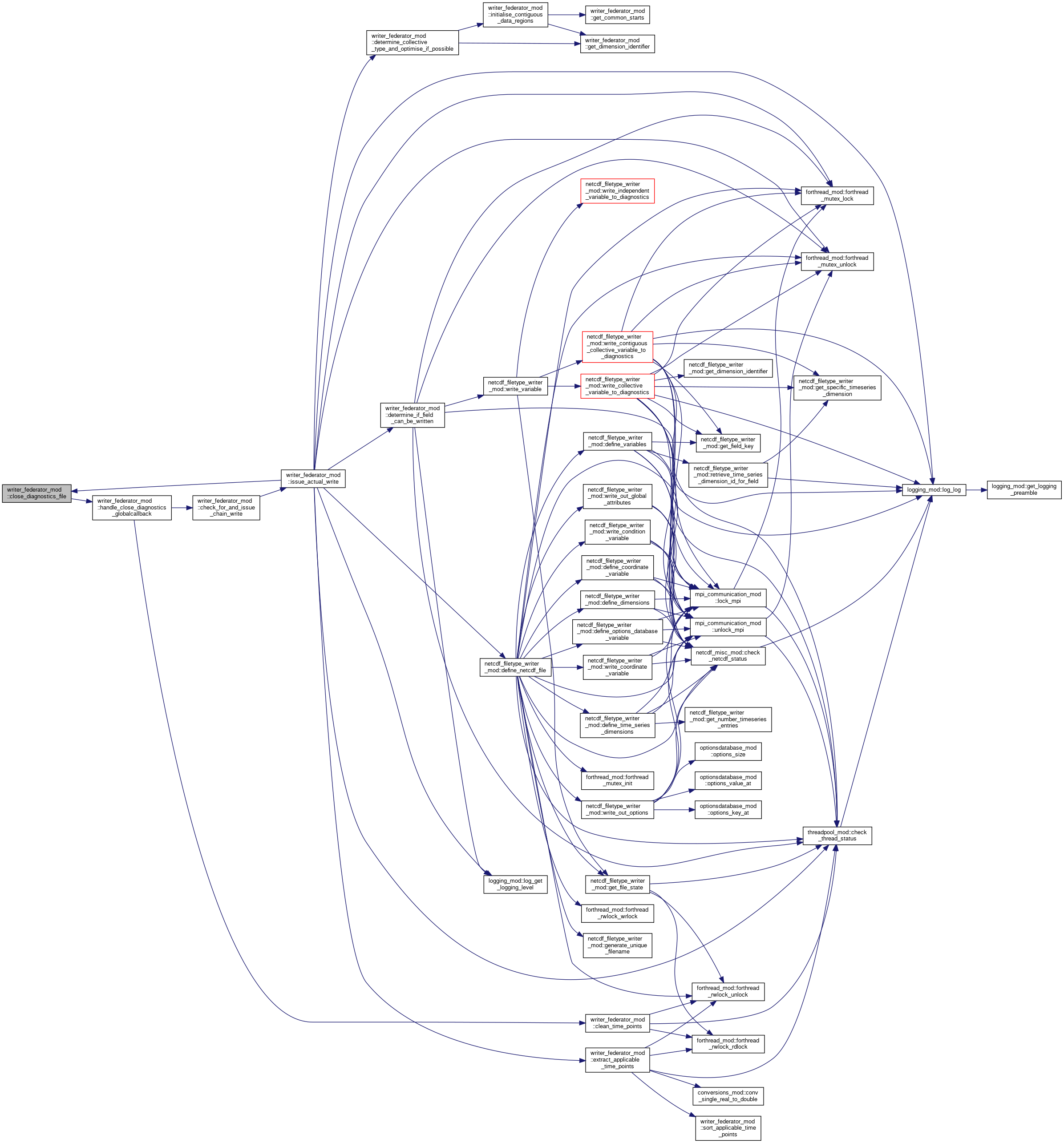

◆ determine_collective_type_and_optimise_if_possible()
|
private |
Determines whether it can optimise a specific collective field. If the field fits into certain limited parameters then it will optimise it. These parameters are very common, hence most fields can be optimised. Basically, it is looking to contiguous blocks of data from different MONCs so that the number of writes to the NetCDF file is limited.
- Parameters
-
io_configuration The IO server configuration field_to_write_information Description of the the specific field that we are looking at here
Definition at line 1423 of file writer_federator.F90.
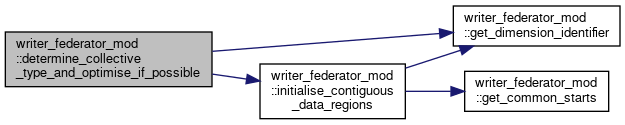

◆ determine_if_field_can_be_written()
|
private |
Determines if a file can be written to its overarching write representation. If so then a write is issued, otherwise an outstanding write point is registered which will be checked frequency to do a write later on.
- Parameters
-
specific_field The specific field we are checking and going to write if possible timestep The current timestep that we are at for this write write_time The current time that we are at for this write field_written An optional output logical representing whether a write was performed or not
Definition at line 573 of file writer_federator.F90.
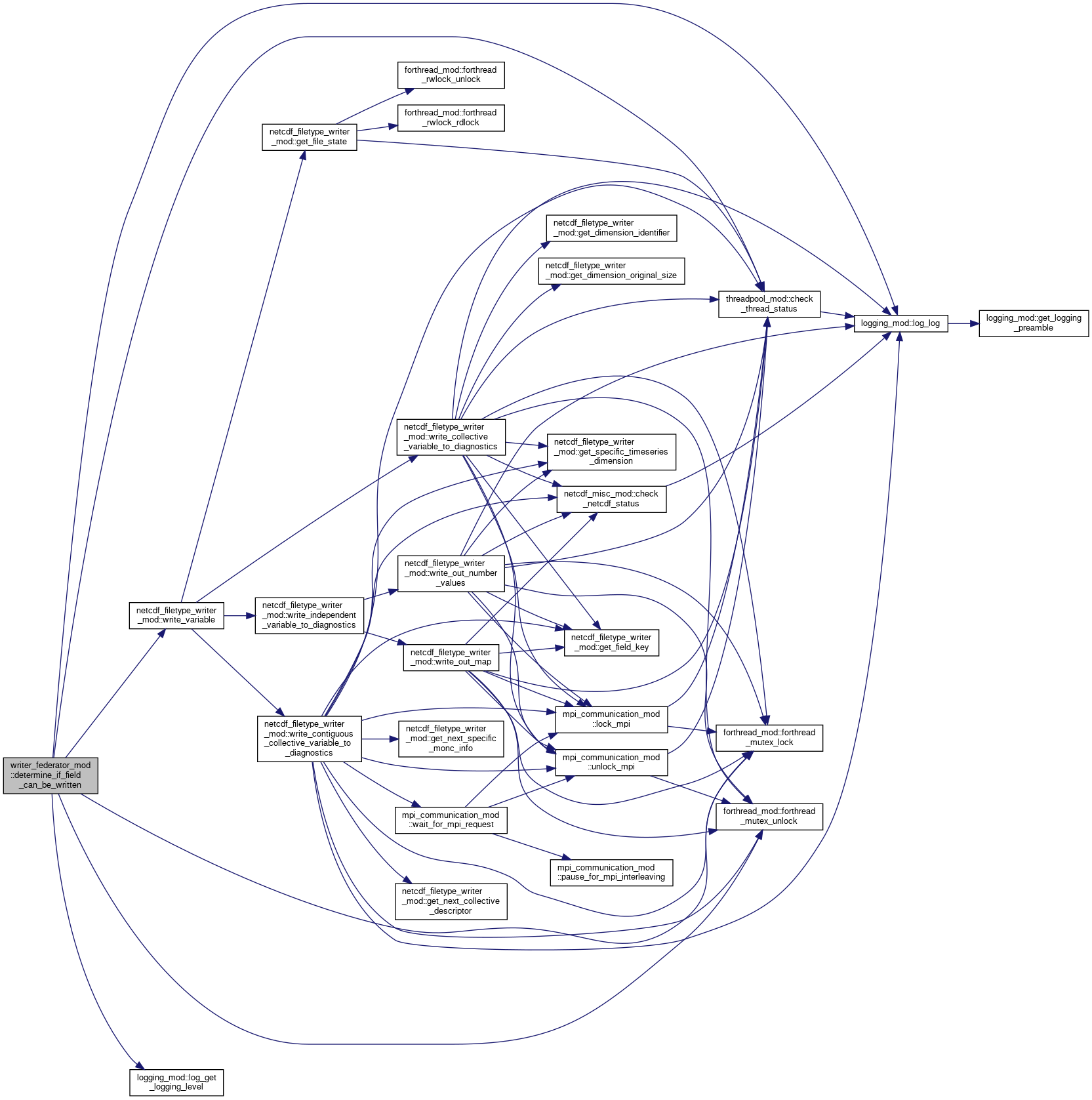

◆ determine_if_outstanding_field_can_be_written()
|
private |
For a specific field wil determine and handle any outstanding fields writes until an outstanding write can not be performed or the outstanding list is empty.
- Parameters
-
specific_field The specific field that we are concerned with
Definition at line 541 of file writer_federator.F90.

◆ enable_specific_field_by_name()
|
private |
Enables a specific field by its name, this will locate all the fields with this name and enable them.
- Parameters
-
field_name The name of the field to enable
Definition at line 247 of file writer_federator.F90.


◆ extract_applicable_time_points()
|
private |
Extracts the applicable time points from the overall map that lie within a specific range.
- Parameters
-
start_time The start time where values must be greater than end_time The end time where values must be equal or less than
- Returns
- The sorted (based on timestep) list of MONC communication time points that correspond to this
Definition at line 822 of file writer_federator.F90.

◆ finalise_writer_federator()
| subroutine, public writer_federator_mod::finalise_writer_federator |
Finalises the write federator and the manipulations.
Definition at line 122 of file writer_federator.F90.

◆ get_common_starts()
|
private |
Retrieves the number of common starting points that match a specific input value.
- Parameters
-
dim The dimension we are searching in val The value that we are looking to match against vals All the other dimensions information to search against common_starters The common starting point locations num_common The number of common starting points identified
Definition at line 1549 of file writer_federator.F90.

◆ get_dimension_identifier()
|
private |
Translates a dimension name to its numeric corresponding identifier.
- Parameters
-
dim_name The name of the dimension to look up is_auto_dimension Optional parameter determining whether dimension is auto or not
- Returns
- Corresponding identifier
Definition at line 1570 of file writer_federator.F90.

◆ get_field_number_of_fields()
|
private |
Retrieves the number of fields that make up this field, if it is a Q field then it will be split into many subfields hence it is not a simple 1-1 mapping.
- Parameters
-
io_configuration The IO server configuration field_name The name of the field num_q_fields The number of Q fields
- Returns
- The number of fields that make up this field
Definition at line 1106 of file writer_federator.F90.

◆ get_group_number_of_fields()
|
private |
Retrieves the number of fields within a group of fields.
- Parameters
-
io_configuration The IO server configuration group_members The members of the group num_q_fields The number of Q fields
- Returns
- The number of fields that make up this group
Definition at line 1082 of file writer_federator.F90.


◆ get_index_of_group()
|
private |
Searches the IO server configuration for a group with a specific name and returns the index to that group or 0 if no corresponding group is found.
- Parameters
-
io_configuration The IO server configuration group_name The group name to look up
- Returns
- The index to this group or 0 if no group is found
Definition at line 1402 of file writer_federator.F90.

◆ get_next_applicable_writer_entry()
|
private |
Retrieves the index of the next writer which uses a specific field. If none is found then returns false, otherwise true.
- Parameters
-
field_name The field name to search for writer_start_point The index that we start searching from result_writer The index of the (next) writer that requires this field is written in here result_contents The index of the contents in the next writer that corresponds to this field
- Returns
- Whether or not a next entry has been found
Definition at line 1017 of file writer_federator.F90.

◆ get_size_of_collective_q()
|
private |
Retrieves the data size for each Q entry of a collective Q field for the specific source MONC that has sent data.
- Parameters
-
io_configuration The IO server configuration field_name The field name to write (if appropriate) source MONC source for the communicated fields
- Returns
- The size (elements) per Q split field
Definition at line 410 of file writer_federator.F90.


◆ get_total_number_writer_fields()
|
private |
Determines the total number of fields that make up a writer entry, this is all the fields of the groups that make up this writer and individual fields specified too.
- Parameters
-
io_configuration The IO server configuration writer_entry_index The index of the writer that we are inquiring about
- Returns
- The total number of fields that make up this writer
Definition at line 1050 of file writer_federator.F90.

◆ handle_close_diagnostics_globalcallback()
|
private |
Call back for the inter IO reduction which actually does the NetCDF file closing which is a collective (synchronous) operation. Calls out to the NetCDF code to do the call and then checks the list of pending file writes to process any others that are waiting in the queue.
- Parameters
-
io_configuration The IO server configuration values The inter IO resulting values, we don't care about these field_name The field name that is being communicated timestep The write timestep
Definition at line 899 of file writer_federator.F90.

◆ handle_duplicate_field_names()
|
private |
Marks duplicate field names in a writer entry as duplicates so that the NetCDF layer can then deal with this by issuing unique names.
- Parameters
-
writer_entry The writer state duplicate_field_names A hashset of duplicate field names which are marked
Definition at line 1384 of file writer_federator.F90.

◆ inform_writer_federator_fields_present()
| subroutine, public writer_federator_mod::inform_writer_federator_fields_present | ( | type(io_configuration_type), intent(inout) | io_configuration, |
| type(hashset_type), intent(inout), optional | field_names, | ||
| type(hashmap_type), intent(inout), optional | diag_field_names_and_roots | ||
| ) |
Informs the writer federator that specific fields are present and should be reflected in the diagnostics output.
- Parameters
-
field_names The set of field names that are present
Definition at line 161 of file writer_federator.F90.


◆ inform_writer_federator_time_point()
| subroutine, public writer_federator_mod::inform_writer_federator_time_point | ( | type(io_configuration_type), intent(inout) | io_configuration, |
| integer, intent(in) | source, | ||
| integer, intent(in) | data_id, | ||
| character, dimension(:), intent(in), allocatable | data_dump | ||
| ) |
Definition at line 131 of file writer_federator.F90.

◆ initialise_contiguous_data_regions()
|
private |
Will initialise the collective data regions that form contiguous blocks within the data. This is quite an expensive operation so only done once for each field, but has the potential for very significant performance advantages for the fields that match it.
- Parameters
-
io_configuration The IO server configuration field_to_write_information The specific field that is being looked at and identified for contiguous data
Definition at line 1444 of file writer_federator.F90.

◆ initialise_writer_federator()
| subroutine, public writer_federator_mod::initialise_writer_federator | ( | type(io_configuration_type), intent(inout) | io_configuration, |
| type(hashmap_type), intent(inout) | diagnostic_generation_frequency, | ||
| logical, intent(in) | continuation_run | ||
| ) |
Initialises the write federator and configures it based on the user configuration. Also initialises the time manipulations.
- Parameters
-
io_configuration The IO server configuration
Definition at line 57 of file writer_federator.F90.

◆ is_field_split_on_q()
| logical function, public writer_federator_mod::is_field_split_on_q | ( | character(len=*), intent(in) | field_name | ) |
Determines whether a field is split on Q or not.
- Parameters
-
field_name The field name to check whether it is being used or not
- Returns
- Whether this field is used or not (and then further split to be constituient parts of Q)
Definition at line 239 of file writer_federator.F90.

◆ is_field_used_by_writer_federator()
| logical function, public writer_federator_mod::is_field_used_by_writer_federator | ( | character(len=*), intent(in) | field_name, |
| character(len=*), intent(in) | field_namespace | ||
| ) |
Determines whether a field is used by the writer federator or not.
- Parameters
-
field_name The field name to check whether it is being used or not
- Returns
- Whether this field is used or not
Definition at line 222 of file writer_federator.F90.


◆ issue_actual_write()
| subroutine, public writer_federator_mod::issue_actual_write | ( | type(io_configuration_type), intent(inout) | io_configuration, |
| type(writer_type), intent(inout) | writer_entry, | ||
| integer, intent(in) | timestep, | ||
| real, intent(in) | time, | ||
| logical, intent(in) | terminated_write | ||
| ) |
Issues the actual file creation, write of available fields and closure if all completed.
- Parameters
-
io_configuration The IO server configuration writer_entry_index Index of the writer we are concerned with timestep The corresponding timestep time The corresponding model time
Definition at line 728 of file writer_federator.F90.

◆ provide_ordered_field_to_writer_federator()
| subroutine, public writer_federator_mod::provide_ordered_field_to_writer_federator | ( | type(io_configuration_type), intent(inout) | io_configuration, |
| character(len=*), intent(in) | field_name, | ||
| character(len=*), intent(in) | field_namespace, | ||
| type(data_values_type), target | field_values, | ||
| integer, intent(in) | timestep, | ||
| real(kind=default_precision), intent(in) | time, | ||
| integer, intent(in) | source | ||
| ) |
Definition at line 311 of file writer_federator.F90.

◆ provide_ordered_field_to_writer_federator_real_values()
|
private |
Provides fields (either diagnostics or prognostics) to the write federator which will action these as appropriate. This will split Q fields up if appropriate.
- Parameters
-
io_configuration The IO server configuration field_name The field name to write (if appropriate) field_values The field values to write (if appropriate) timestep Corresponding MONC timestep time Corresponding MONC model time source Optional MONC source for the communicated fields
Definition at line 371 of file writer_federator.F90.

◆ provide_ordered_single_field_to_writer_federator()
|
private |
Provides a single ordered field, i.e. Q fields have been split by this point.
- Parameters
-
io_configuration The IO server configuration field_name The field name to write (if appropriate) field_values The field values to write (if appropriate) timestep Corresponding MONC timestep time Corresponding MONC model time source Optional MONC source for the communicated fields
Definition at line 437 of file writer_federator.F90.

◆ provide_q_field_names_to_writer_federator()
| subroutine, public writer_federator_mod::provide_q_field_names_to_writer_federator | ( | type(list_type), intent(inout) | q_provided_field_names | ) |
Provides the Q field names to the write federator, this is required as on initialisation we don't know what these are and only when MONC register do they inform the IO server of the specifics.
- Parameters
-
q_field_names An ordered list of Q field names
Definition at line 277 of file writer_federator.F90.


◆ register_pending_file_write()
|
private |
Registers a pending file write which will be actioned later on.
- Parameters
-
writer_entry_index Index of the writer entry timestep The timestep that the pending write represents time The time of the pending write
Definition at line 992 of file writer_federator.F90.

◆ sort_applicable_time_points()
|
private |
Sorts the time points based upon their timestep, smallest to largest. Note that this is a bubble sort and as such inefficient, so would be good to change to something else but works OK for now.
- Parameters
-
unsorted_timepoints The unsorted timepoints, which is changed by destroying the map
- Returns
- The sorted version of the input map based upon timestep
Definition at line 846 of file writer_federator.F90.

◆ write_collective_write_value()
|
private |
Writes the collective values, this is held differently to independent values which are written directly - instead here we need to store the values for each MONC hence a specific type is used instead.
- Parameters
-
result_values The data values to store writer_index The file writer index contents_index The contents index source The MONC process id lookup_key The values lookup key
Definition at line 515 of file writer_federator.F90.

Variable Documentation
◆ collective_contiguous_initialisation_mutex
|
private |
Definition at line 47 of file writer_federator.F90.
◆ collective_q_field_dims
|
private |
Definition at line 45 of file writer_federator.F90.
◆ currently_writing
|
private |
Definition at line 48 of file writer_federator.F90.
◆ currently_writing_mutex
|
private |
Definition at line 47 of file writer_federator.F90.
◆ q_field_names
|
private |
Definition at line 44 of file writer_federator.F90.
◆ q_field_splits
|
private |
Definition at line 45 of file writer_federator.F90.
◆ time_points
|
private |
Definition at line 45 of file writer_federator.F90.
◆ time_points_rwlock
|
private |
Definition at line 47 of file writer_federator.F90.
◆ used_field_names
|
private |
Definition at line 44 of file writer_federator.F90.
◆ writer_entries
|
private |
Definition at line 43 of file writer_federator.F90.